Text prompts are NOT enough. We need a new generation of creative tools to truly tame generative AI. Tools that allow us to sculpt, paint, act, and speak new worlds and stories into existence with the power of human creativity and AI combined. The scene in the video was made… twitter.com/i/web/status/1… pic.twitter.com/7lz6JkqgK8
JSON format is becoming the de facto standard for output generation with LLM. However, is it the optimal format ? 🤔 We claim that not - YAML outputs are shorter and simpler, leading to faster inference, with higher quality: pic.twitter.com/gJkjzH0edB

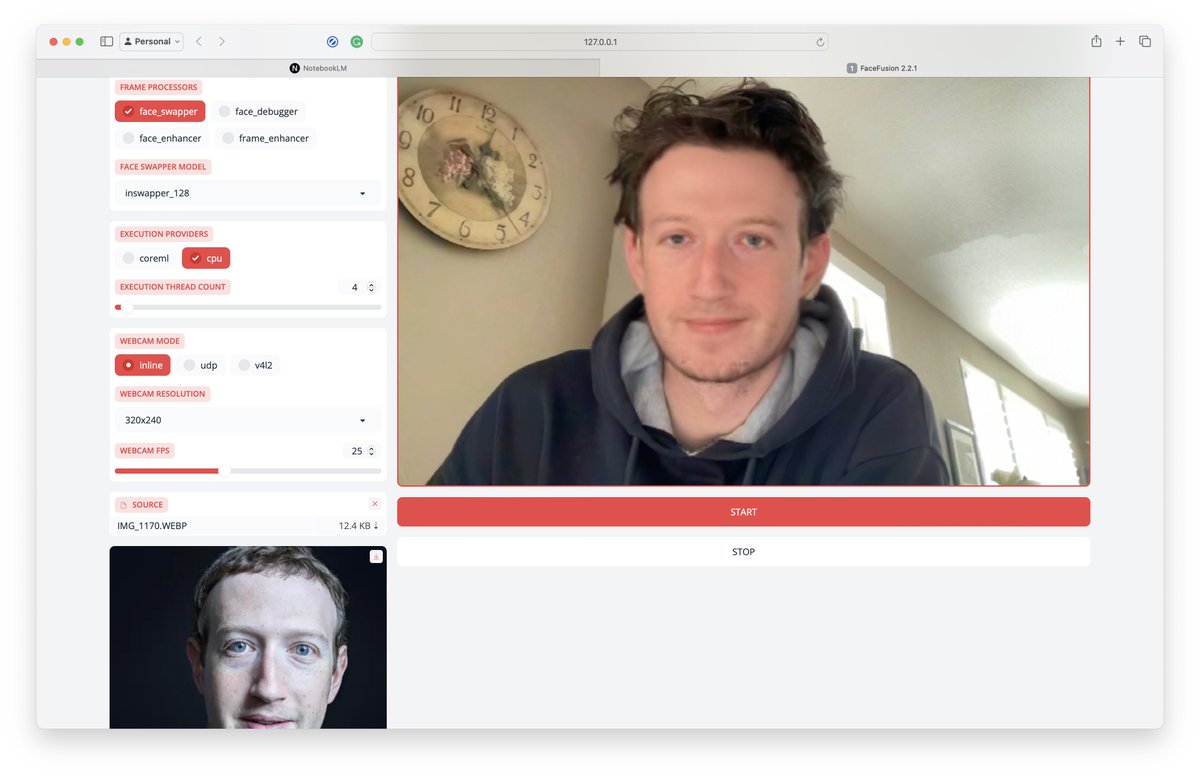
Real time deep fakes running locally on M1 Pro. Im scared...😳 Using github.com/facefusion/fac… On pinokio.computer pic.twitter.com/epWYyBcgQ3
Nah, gpt-4 level models on a phone are very far out like years away type of far out. Not sure if people realize how bad small models are in actual use as an "assistant"
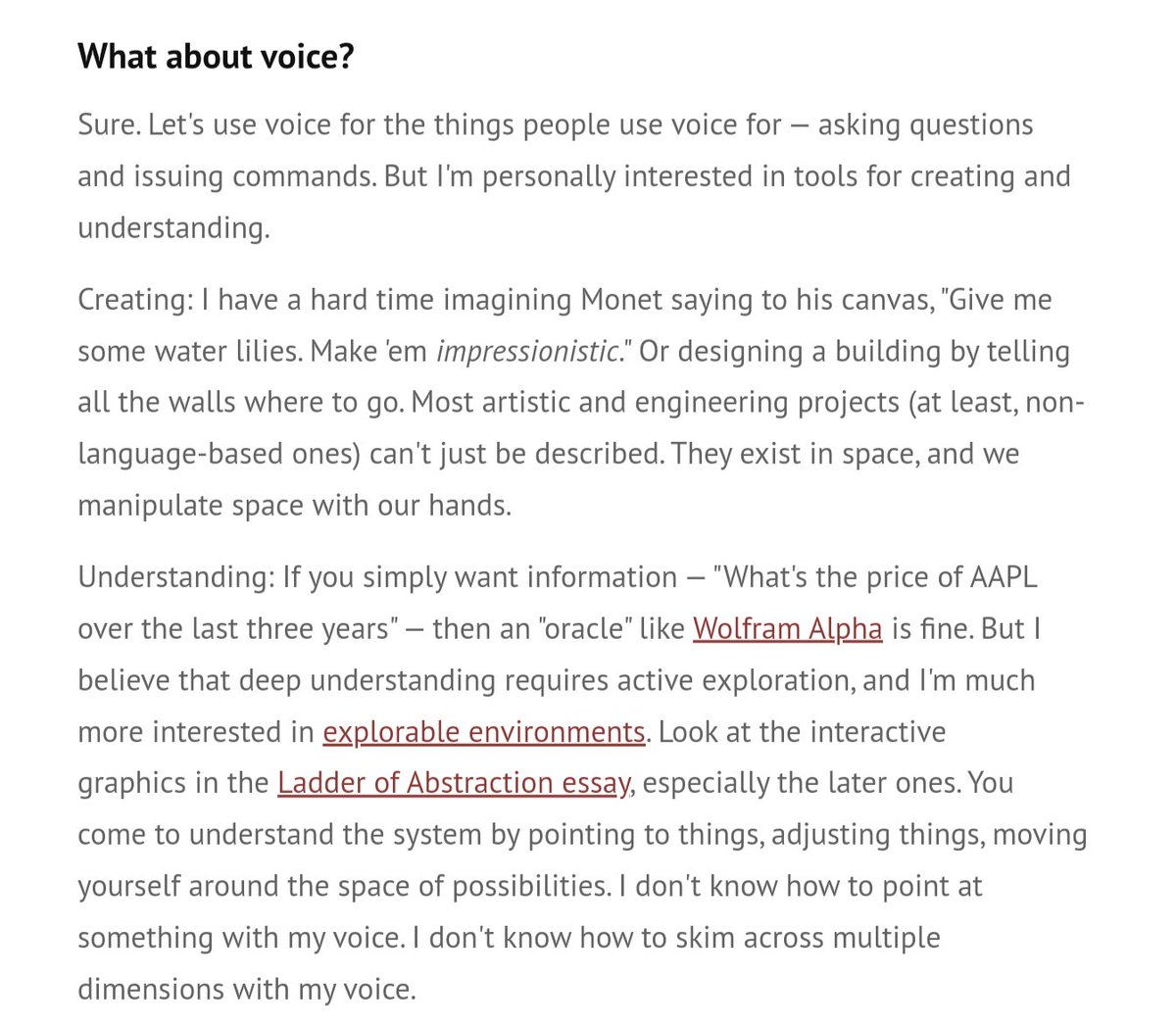
Before you start a consumer hardware company with voice as your input modality, read this pic.twitter.com/Yv1tMY2tGu
Agents will largely be solved this year. The ones that operate a desktop, browser or phone automatically when given a task. I think it’s just a matter of time
AI interfaces should go beyond a chatbot: generative UI is next. Here's a demo of a library for LLMs that I've been working on. It prompts models with a vocabulary of rich components described using natural language. Presented at @causalislands last week. pic.twitter.com/5H1WUQwYBU
This chart is very useful if you want to get AI to do anything complicated. It explains the two currently most advanced ways to prompt LLMs: multiple shot chain of thought (give it examples in the prompt) & step-by-step (ask it to go step-by-step) Combining the two worked best. pic.twitter.com/3xrpwbBq4t twitter.com/johnjnay/statu…

🧠 Two-Shot Chain of Thought Reasoning + Step-by-Step Thinking: New prompting technique boosts LLMs accuracy up to 80%. GPT-4 even hits a perfect 100% score. But what does this mean for you? 🤔 Let's explore how this approach can enhance everyday scenarios with ChatGPT. 🚀 pic.twitter.com/NUgzUnqbD8

True or false? And what is missing? pic.twitter.com/K5G3y3Lxkz
This is the best text to speech I've heard - bravo! We are officially at indistinguishable from a human levels. suno-ai.notion.site/Bark-Examples-…
Delighted to announce our investment in Create (create.xyz), an AI-powered tool that helps ambitious entrepreneurs, teams, and companies launch new software products faster. Their mission is to give *everyone* the power of software creation. medium.com/uncorkcapital/…
I improved Amazon Alexa 1000x by replacing it with ChatGPT pic.twitter.com/x38DyB6X6C
✨ New: Text to shareable web apps. Transform natural language into simple apps, UI, widgets, websites, games, forms – LITERALLY ANYTHING. Not just calculators, but fully featured web apps. 🪄 literallyanything.io (desktop only for now) Something we’ve been iterating on… twitter.com/i/web/status/1… pic.twitter.com/cq5j3qmMP0
AI tools that will change the way you work (save your time): 1. Stockimg.ai ➝ Design 2. Codeium.com ➝ Code 3. Tugan.ai ➝ URL to marketing emails 4. Stunning.so ➝ Text to website 5. Rytr.me ➝ Content
ChatGPT for Healthcare 🤯 When LLMs meet clinical expertise, you get the ultimate AI powered diagnostic and treatment tool. Combining a powerful language model with a clinical knowledge, Glass AI 2.0 will revolutionize the way doctors pic.twitter.com/I2bKzRJ9BT… twitter.com/i/web/status/1…
I recently added a multiple PDF file upload feature to the gpt4 pdf repo. Now you can 'chat' with multiple large PDF docs. 3,400 stars so far and still climbing 🙏 code: github.com/mayooear/gpt4-… twitter.com/mayowaoshin/st…
Genmo Chat, a copilot to create and edit videos with text using GPT-4. link: genmo.ai Demo video “Snack to the Future” pic.twitter.com/Gq8qMB89Cd
5 AI websites to increase productivity 👇👇 100+ collection of AI tools vondy.com Trigger app automations bardeen.ai Create your branding looka.com Build AI web apps buildai.space Track your progress focusflow.ai pic.twitter.com/6K7sBDO3OP
4 AI tools that'll save you hours a day at work: 1. sourceai.dev Generate code with AI 2. otter.ai Takes virtual meeting notes in real time 3. steve.ai Create video with AI 4. heyfriday.ai/home Writing is as easy as Friday
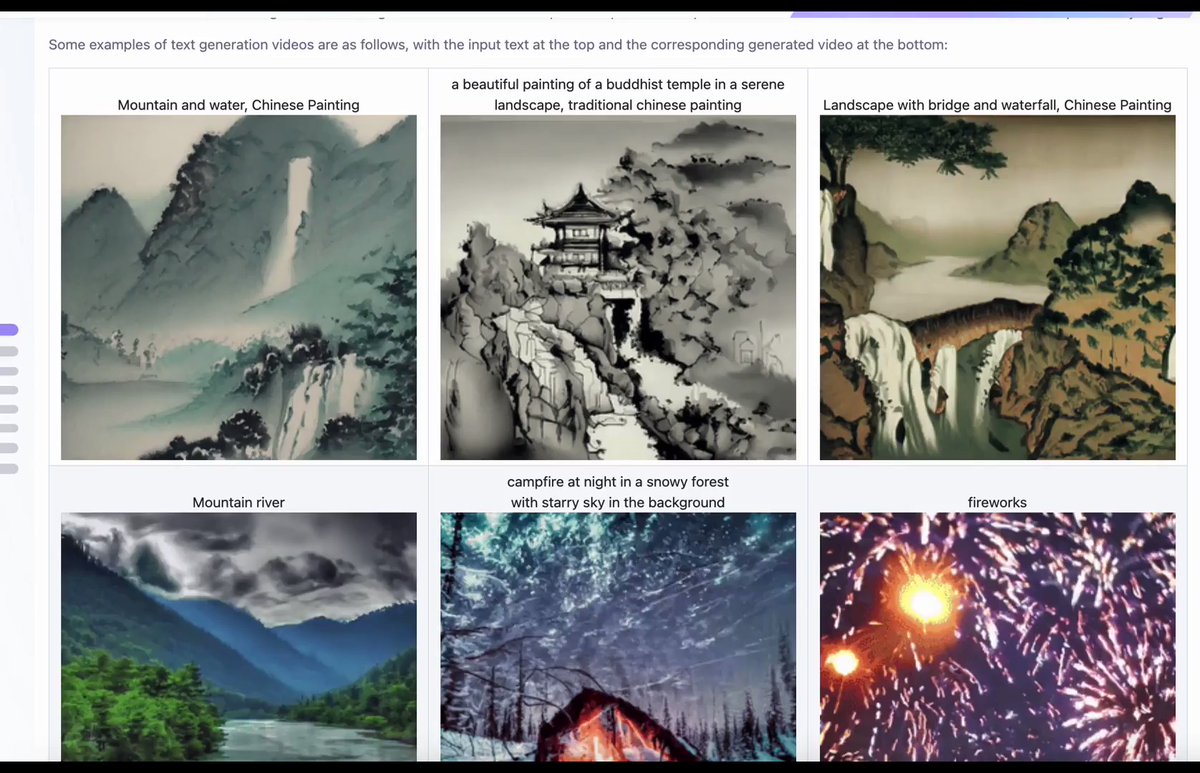
Big News: The first Open-Source #txt2video 1.7 billion parameter diffusion model has been released and you can play with it now at HuggingFace: huggingface.co/spaces/damo-vi… More examples here and you can git clone from here too (if you have the VRAM). modelscope.cn/models/damo/te… #aiart… twitter.com/i/web/status/1… pic.twitter.com/rLmdxNDdJV
Nice summary of what I think is the most interesting way to use GPT at the moment: in an iterative loop, in conversation with other tools. It’s wild that this works. twitter.com/intrcnnctd/sta…
1/7 Spent the week-end with ControlNet, a new approach to have precise, fine-grained control over image generation with diffusion models. It's huge step forward and will change a number of industries. Here is an example. pic.twitter.com/9iJ9G8H50m

Eleven Labs has the most realistic AI text-to-voice platform I’ve seen. beta.elevenlabs.io (free to try) It’s 99% perfect. Generates great inflection, cadence, and natural pauses. Sample: pic.twitter.com/nf0agi4QTK
After tons of research and experimentation, here are the 6 types of information I provide in my ChatGPT mega-prompts: pic.twitter.com/dQbcAUQ0dy

I've launched a new website 🥳 It's a resource of ai-powered tools & services. Check it out at allthingsai.com pic.twitter.com/ZFOHs5RXMf
I wrote a guide, 'Fine tuning StableDiffusion v2.0 with DreamBooth' cc: @EMostaque @StabilityAI @NerdyRodent @KaliYuga_ai @amli_art @ykilcher @StableDiffusion @DiffusionPics @hashnode @sharifshameem @bl_artcult #stablediffusion2 #stablediffusion dushyantmin.com/fine-tuning-st…
We are excited to announce the release of Stable Diffusion Version 2! Stable Diffusion V1 changed the nature of open source AI & spawned hundreds of other innovations all over the world. We hope V2 also provides many new possibilities! Link → stability.ai/blog/stable-di… pic.twitter.com/z0yu3FDWB5

hyperpersonalized AI models are pretty exciting you can easily fine tune stablediffusion to consistently create multitudes of any sort of niche thing via dreambooth et al i wonder how many sufficiently distinct vibe-tunes "exist"? enjoying my new weird-synthstruments model: pic.twitter.com/eTCMobIKwl

Hello world! We’re launching our first product, MultiFlow. flow.multi.tech MultiFlow makes it easy to create, deploy, and rapidly iterate on generative AI workflows. pic.twitter.com/wKHpUZcoGv
